What is Hadoop? Hadoop Cluster configuration in Linux.
Introduction:
In the world of big data, whenever we talk about databases, servers and processing the first tool that comes to our mind is Hadoop. If you’re new in the field of big data analytics, sooner or later you will come across Hadoop because it has its own significance in the field of big data. Due to its great performance, features and flexibility it is widely used in the world of big data. So what is Hadoop?
In this post, I will demonstrate how to configure a Hadoop cluster in Linux.
Apache Hadoop:
There are multiple definitions that describe Hadoop but what I found the most accurate is as follows.
Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware. It provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs.

Hadoop is the center of the growing ecosystem of big data technologies that are used to support advanced analytics, data mining and machine learning applications. Apache Hadoop, the technology is developed as part of an open-source project within the Apache Software Foundation. Hadoop is called the backbone of big data because of its great flexibility that it can be integrated with a lot of other big data tools like Apache Hive, Apache Ignite, Presto, Impala, Apache Druid, etc .
Let’s discuss Hadoop in detail about its components and other amazing features.
Components of Hadoop:
Hadoop has four main core components that make it worth. Each component carries out a particular task essential for a computer system designed for big data analytics.
Distributed File System:
This is one of the reasons why Hadoop is unique, Hadoop Distributed File System (HDFS) allows data to be stored in an easily accessible format across a large number of linked devices. The process of connecting devices together and sharing resources with each other is called Clustering. No matter how many devices are connected in a cluster they will that single Distributed File System through a U.I and a port.
![]()
MapReduce:
One of the other reasons for Hadoop’s great performance is its component MapReduce. MapReduce is named after the two basic operations this module carries out — reading data from the database, putting it into a format suitable for analysis (map), and performing mathematical operations i.e counting the number of males aged 30+ in a customer database (reduce). Whenever the MapReduce process is running it is called Job. The Mapper and Reducer code can be written in Java and Python and can easily be run through Hadoop, however, to run on Python, a “hadoop streaming jar” file is needed.
![]()
Hadoop Common:
The other component is Hadoop Common, which provides the tools (in Java) needed for the user’s computer systems (Windows, Unix or whatever) to read data stored under the Hadoop file system.
![]()
YARN:
The final and most integral component of Hadoop is Yet Another Resource Negotiator (YARN). YARN is responsible for managing resources of the system storing the data and running the analysis. We can allocate resources to different processes in the Hadoop cluster. Yarn has three different schedulers that schedule jobs in different ways, FIFO (First In First Out), Fair Scheduler & Capacity Scheduler.

Why is Hadoop Important?
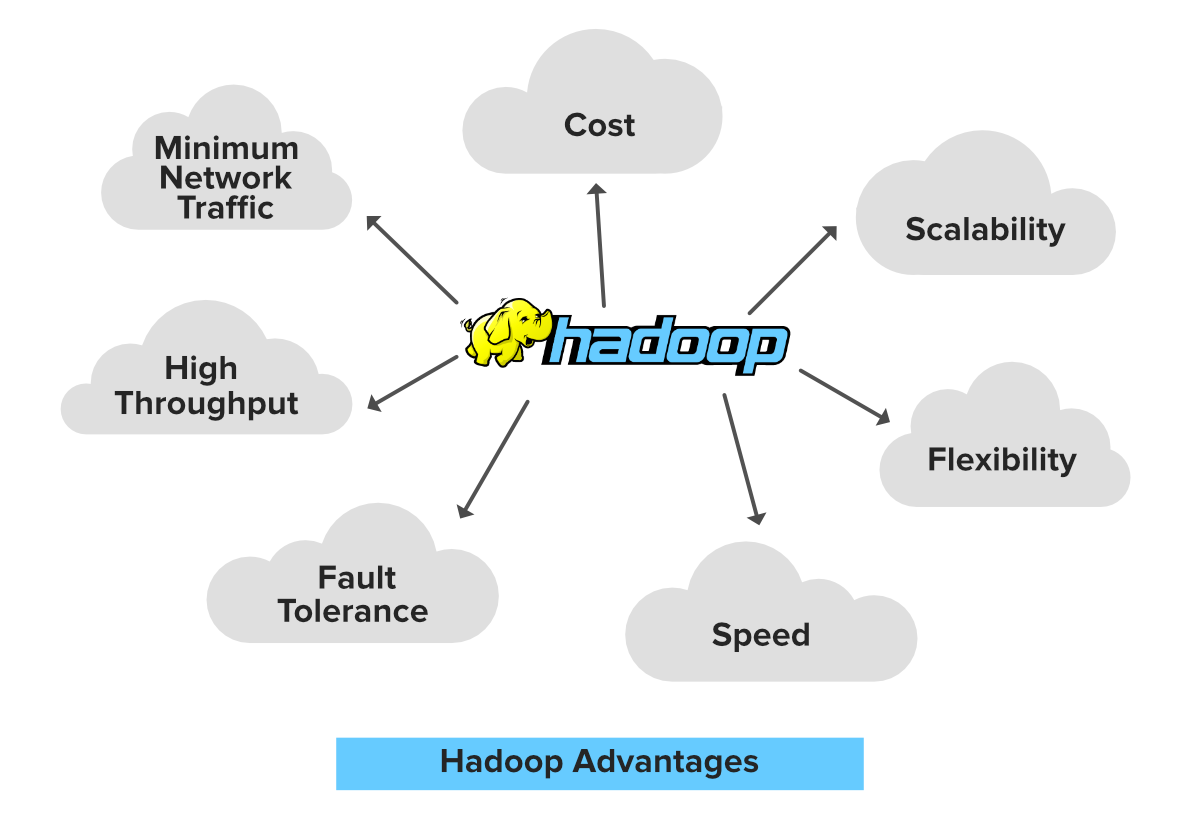
- Ability to store and process huge amounts of any kind of data, quickly. With data volumes and varieties constantly increasing, especially from social media and the Internet of Things (IoT), that’s a key consideration.
- Computing power. Hadoop’s distributed computing model processes big data fast. The more computing nodes you use, the more processing power you have.
- Fault tolerance. Data and application processing are protected against hardware failure. If a node goes down, jobs are automatically redirected to other nodes to make sure the distributed computing does not fail. Multiple copies of all data are stored automatically.
- Flexibility. Unlike traditional relational databases, you don’t have to preprocess data before storing it. You can store as much data as you want and decide how to use it later. That includes unstructured data like text, images and videos.
- Low cost. The open-source framework is free and uses commodity hardware to store large quantities of data.
- Scalability. You can easily grow your system to handle more data simply by adding nodes. Little administration is required.
At this point I hope you understand Hadoop and what makes it unique to be widely used in big data. Now lets move on to Hadoop Cluster Deployment in Linux.
Configure Hadoop Cluster in Linux :
To configure a multi-node Hadoop cluster is very simple and easy. Just follow the instructions given below.
- First of all make sure that Java (open jdk) version 8 is installed, if not, open gnome-terminal and enter command “sudo apt-get install openjdk-8-jdk”.
- Set up PATH and JAVA_HOME variables in ~/.bashrc file
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=PATH:$JAVA_HOME/bin
3. Create a system user account on both master and slave systems to use the Hadoop installation. Login as root user “su root” then create a user..
useradd hadoop
(after executing it, set the password).
4. Make sure your master node knows other nodes by their ip and hostnames, in order to do it
# vi /etc/hosts
enter the following lines in the /etc/hosts file.
192.168.1.109 hadoop-master
192.168.1.145 hadoop-slave-1
192.168.56.1 hadoop-slave-2
5. Setup ssh in every node such that they can communicate with one another without any prompt for the password.
# su hadoop
$ ssh-keygen -t rsa
$ ssh-copy-id -i ~/.ssh/id_rsa.pub tutorialspoint@hadoop-master
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp1@hadoop-slave-1
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp2@hadoop-slave-2
$ chmod 0600 ~/.ssh/authorized_keys
$ exit
6. Install Hadoop 2.7 because it doesn’t have any compatibility issues with other tools. Install Hadoop 2.7 Binar form here. After downloading it untar the file
tar -xzf hadoop-2.7.0.tar.gz
7. Set PATH and HADOOP HOME variable in ~/.bashrc file.
export HADOOP_HOME=<path to hadoop's directory>
export PATH=PATH:$HADOOP_HOME/bin
8. Configure Master node
$ vi etc/hadoop/masters
hadoop-master
9. Configure Slave node
$ vi etc/hadoop/slaves
hadoop-slave-1
hadoop-slave-2
10. Format Namenode on master node. Go to Hadoop’s bin directory and type..
./hadoop namenode –format
Finally after doing all the above procedures start hadoop services .
$ cd $HADOOP_HOME/sbin
$ start-all.sh
At this point, hopefully, you should have deployed Hadoop Multi-node Cluster.